


Raft 算法-分布式协议&算法
1 背景
当今的数据中心和应用程序在高度动态的环境中运行,为了应对高度动态的环境,它们通过额外的服务器进行横向扩展,并且根据需求进行扩展和收缩。同时,服务器和网络故障也很常见。
因此,系统必须在正常操作期间处理服务器的上下线。它们必须对变故做出反应并在几秒钟内自动适应;对客户来说的话,明显的中断通常是不可接受的。
幸运的是,分布式共识可以帮助应对这些挑战。
1.1 拜占庭将军
在介绍共识算法之前,先介绍一个简化版拜占庭将军的例子来帮助理解共识算法。
假设多位拜占庭将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成是否要进攻的一致性决定?
解决方案大致可以理解成:先在所有的将军中选出一个大将军,用来做出所有的决定。
举例如下:假如现在一共有 3 个将军 A,B 和 C,每个将军都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军 B 和 C,如果将军 B 和 C 还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军 A,信使回到将军 A 时,将军 A 知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军 A 决定,然后再去派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军 B 和 C 的回复(信使可能会被暗杀),那就再重派一个信使,直到收到回复。
1.2 共识算法
共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
共识算法允许一组节点像一个整体一样一起工作,即使其中的一些节点出现故障也能够继续工作下去,其正确性主要是源于复制状态机的性质:一组Server的状态机计算相同状态的副本,即使有一部分的Server宕机了它们仍然能够继续运行。
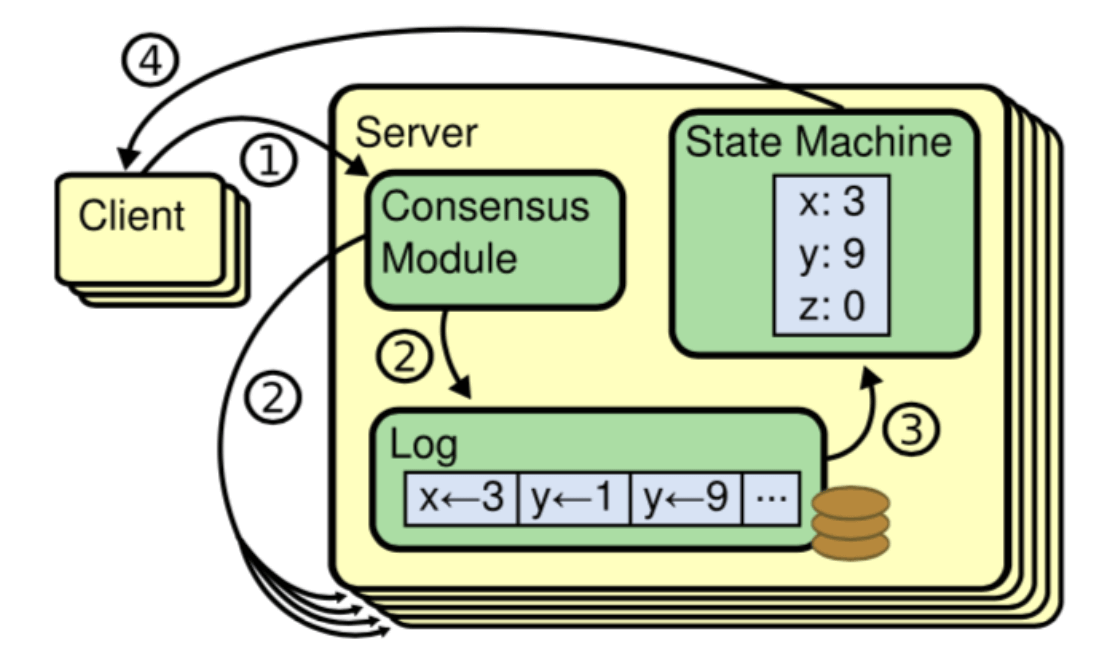
图-1 复制状态机架构
一般通过使用复制日志来实现复制状态机。每个Server存储着一份包括命令序列的日志文件,状态机会按顺序执行这些命令。因为每个日志包含相同的命令,并且顺序也相同,所以每个状态机处理相同的命令序列。由于状态机是确定性的,所以处理相同的状态,得到相同的输出。
因此共识算法的工作就是保持复制日志的一致性。服务器上的共识模块从客户端接收命令并将它们添加到日志中。它与其他服务器上的共识模块通信,以确保即使某些服务器发生故障。每个日志最终包含相同顺序的请求。一旦命令被正确地复制,它们就被称为已提交。每个服务器的状态机按照日志顺序处理已提交的命令,并将输出返回给客户端,因此,这些服务器形成了一个单一的、高度可靠的状态机。
适用于实际系统的共识算法通常具有以下特性:
安全。确保在非拜占庭条件(也就是上文中提到的简易版拜占庭)下的安全性,包括网络延迟、分区、包丢失、复制和重新排序。
高可用。只要大多数服务器都是可操作的,并且可以相互通信,也可以与客户端进行通信,那么这些服务器就可以看作完全功能可用的。因此,一个典型的由五台服务器组成的集群可以容忍任何两台服务器端故障。假设服务器因停止而发生故障;它们稍后可能会从稳定存储上的状态中恢复并重新加入集群。
一致性不依赖时序。错误的时钟和极端的消息延迟,在最坏的情况下也只会造成可用性问题,而不会产生一致性问题。
在集群中大多数服务器响应,命令就可以完成,不会被少数运行缓慢的服务器来影响整体系统性能。
2 基础
2.1 节点类型
一个 Raft 集群包括若干服务器,以典型的 5 服务器集群举例。在任意的时间,每个服务器一定会处于以下三个状态中的一个:
Leader:负责发起心跳,响应客户端,创建日志,同步日志。Candidate:Leader 选举过程中的临时角色,由 Follower 转化而来,发起投票参与竞选。Follower:接受 Leader 的心跳和日志同步数据,投票给 Candidate。
在正常的情况下,只有一个服务器是 Leader,剩下的服务器是 Follower。Follower 是被动的,它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。
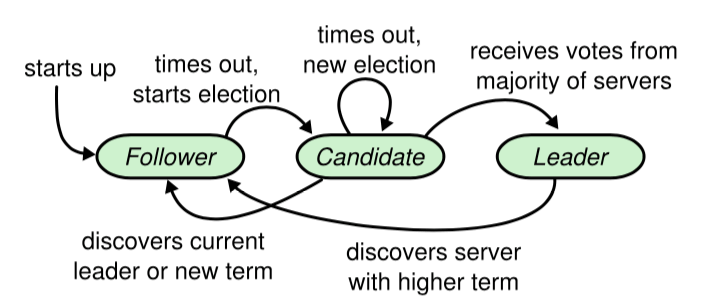
图-2:服务器的状态
2.2 任期
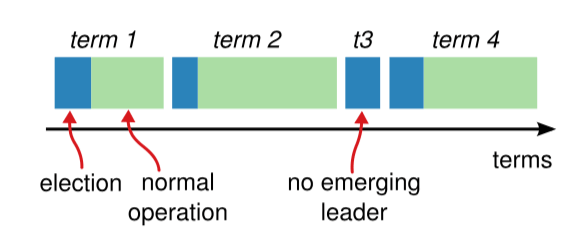
图-3:任期
如图 3 所示,raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader,将会开启另一个任期,并立刻开始下一次选举。raft 算法保证在给定的一个任期最少要有一个 Leader。
每个节点都会存储当前的 term 号,当服务器之间进行通信时会交换当前的 term 号;如果有服务器发现自己的 term 号比其他人小,那么他会更新到较大的 term 值。如果一个 Candidate 或者 Leader 发现自己的 term 过期了,他会立即退回成 Follower。如果一台服务器收到的请求的 term 号是过期的,那么它会拒绝此次请求。
2.3 日志
entry:每一个事件成为 entry,只有 Leader 可以创建 entry。entry 的内容为<term,index,cmd>其中 cmd 是可以应用到状态机的操作。log:由 entry 构成的数组,每一个 entry 都有一个表明自己在 log 中的 index。只有 Leader 才可以改变其他节点的 log。entry 总是先被 Leader 添加到自己的 log 数组中,然后再发起共识请求,获得同意后才会被 Leader 提交给状态机。Follower 只能从 Leader 获取新日志和当前的 commitIndex,然后把对应的 entry 应用到自己的状态机中。
3 领导人选举
raft 使用心跳机制来触发 Leader 的选举。
如果一台服务器能够收到来自 Leader 或者 Candidate 的有效信息,那么它会一直保持为 Follower 状态,并且刷新自己的 electionElapsed,重新计时。
Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader 地位。如果一个 Follower 在一个周期内没有收到心跳信息,就叫做选举超时,然后它就会认为此时没有可用的 Leader,并且开始进行一次选举以选出一个新的 Leader。
为了开始新的选举,Follower 会自增自己的 term 号并且转换状态为 Candidate。然后他会向所有节点发起 RequestVoteRPC 请求, Candidate 的状态会持续到以下情况发生:
赢得选举 其他节点赢得选举 一轮选举结束,无人胜出
赢得选举的条件是:一个 Candidate 在一个任期内收到了来自集群内的多数选票(N/2+1),就可以成为 Leader。
在 Candidate 等待选票的时候,它可能收到其他节点声明自己是 Leader 的心跳,此时有两种情况:
该 Leader 的 term 号大于等于自己的 term 号,说明对方已经成为 Leader,则自己回退为 Follower。 该 Leader 的 term 号小于自己的 term 号,那么会拒绝该请求并让该节点更新 term。
由于可能同一时刻出现多个 Candidate,导致没有 Candidate 获得大多数选票,如果没有其他手段来重新分配选票的话,那么可能会无限重复下去。
raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的枚举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
4 日志复制
一旦选出了 Leader,它就开始接受客户端的请求。每一个客户端的请求都包含一条需要被复制状态机(Replicated State Mechine)执行的命令。
Leader 收到客户端请求后,会生成一个 entry,包含<index,term,cmd>,再将这个 entry 添加到自己的日志末尾后,向所有的节点广播该 entry,要求其他服务器复制这条 entry。
如果 Follower 接受该 entry,则会将 entry 添加到自己的日志后面,同时返回给 Leader 同意。
如果 Leader 收到了多数的成功响应,Leader 会将这个 entry 应用到自己的状态机中,之后可以成为这个 entry 是 committed 的,并且向客户端返回执行结果。
raft 保证以下两个性质:
在两个日志里,有两个 entry 拥有相同的 index 和 term,那么它们一定有相同的 cmd 在两个日志里,有两个 entry 拥有相同的 index 和 term,那么它们前面的 entry 也一定相同
通过“仅有 Leader 可以生存 entry”来保证第一个性质,第二个性质需要一致性检查来进行保证。
一般情况下,Leader 和 Follower 的日志保持一致,然后,Leader 的崩溃会导致日志不一样,这样一致性检查会产生失败。Leader 通过强制 Follower 复制自己的日志来处理日志的不一致。这就意味着,在 Follower 上的冲突日志会被领导者的日志覆盖。
为了使得 Follower 的日志和自己的日志一致,Leader 需要找到 Follower 与它日志一致的地方,然后删除 Follower 在该位置之后的日志,接着把这之后的日志发送给 Follower。
Leader 给每一个Follower 维护了一个 nextIndex,它表示 Leader 将要发送给该追随者的下一条日志条目的索引。当一个 Leader 开始掌权时,它会将 nextIndex 初始化为它的最新的日志条目索引数+1。如果一个 Follower 的日志和 Leader 的不一致,AppendEntries 一致性检查会在下一次 AppendEntries RPC 时返回失败。在失败之后,Leader 会将 nextIndex 递减然后重试 AppendEntries RPC。最终 nextIndex 会达到一个 Leader 和 Follower 日志一致的地方。这时,AppendEntries 会返回成功,Follower 中冲突的日志条目都被移除了,并且添加所缺少的上了 Leader 的日志条目。一旦 AppendEntries 返回成功,Follower 和 Leader 的日志就一致了,这样的状态会保持到该任期结束。
5 安全性
5.1 选举限制
Leader 需要保证自己存储全部已经提交的日志条目。这样才可以使日志条目只有一个流向:从 Leader 流向 Follower,Leader 永远不会覆盖已经存在的日志条目。
每个 Candidate 发送 RequestVoteRPC 时,都会带上最后一个 entry 的信息。所有节点收到投票信息时,会对该 entry 进行比较,如果发现自己的更新,则拒绝投票给该 Candidate。
判断日志新旧的方式:如果两个日志的 term 不同,term 大的更新;如果 term 相同,更长的 index 更新。
5.2 节点崩溃
如果 Leader 崩溃,集群中的节点在 electionTimeout 时间内没有收到 Leader 的心跳信息就会触发新一轮的选主,在选主期间整个集群对外是不可用的。
如果 Follower 和 Candidate 崩溃,处理方式会简单很多。之后发送给它的 RequestVoteRPC 和 AppendEntriesRPC 会失败。由于 raft 的所有请求都是幂等的,所以失败的话会无限的重试。如果崩溃恢复后,就可以收到新的请求,然后选择追加或者拒绝 entry。
5.3 时间与可用性
raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为一些事件发生的比预想的快一些或者慢一些就产生错误。为了保证上述要求,最好能满足以下的时间条件:
broadcastTime << electionTimeout << MTBF
broadcastTime:向其他节点并发发送消息的平均响应时间;electionTimeout:选举超时时间;MTBF(mean time between failures):单台机器的平均健康时间;
broadcastTime应该比electionTimeout小一个数量级,为的是使Leader能够持续发送心跳信息(heartbeat)来阻止Follower开始选举;
electionTimeout也要比MTBF小几个数量级,为的是使得系统稳定运行。当Leader崩溃时,大约会在整个electionTimeout的时间内不可用;我们希望这种情况仅占全部时间的很小一部分。
由于broadcastTime和MTBF是由系统决定的属性,因此需要决定electionTimeout的时间。
一般来说,broadcastTime 一般为 0.5~20ms,electionTimeout 可以设置为 10~500ms,MTBF 一般为一两个月。
6 参考
https://tanxinyu.work/raft/ https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md https://github.com/ongardie/dissertation/blob/master/stanford.pdf https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
评论区